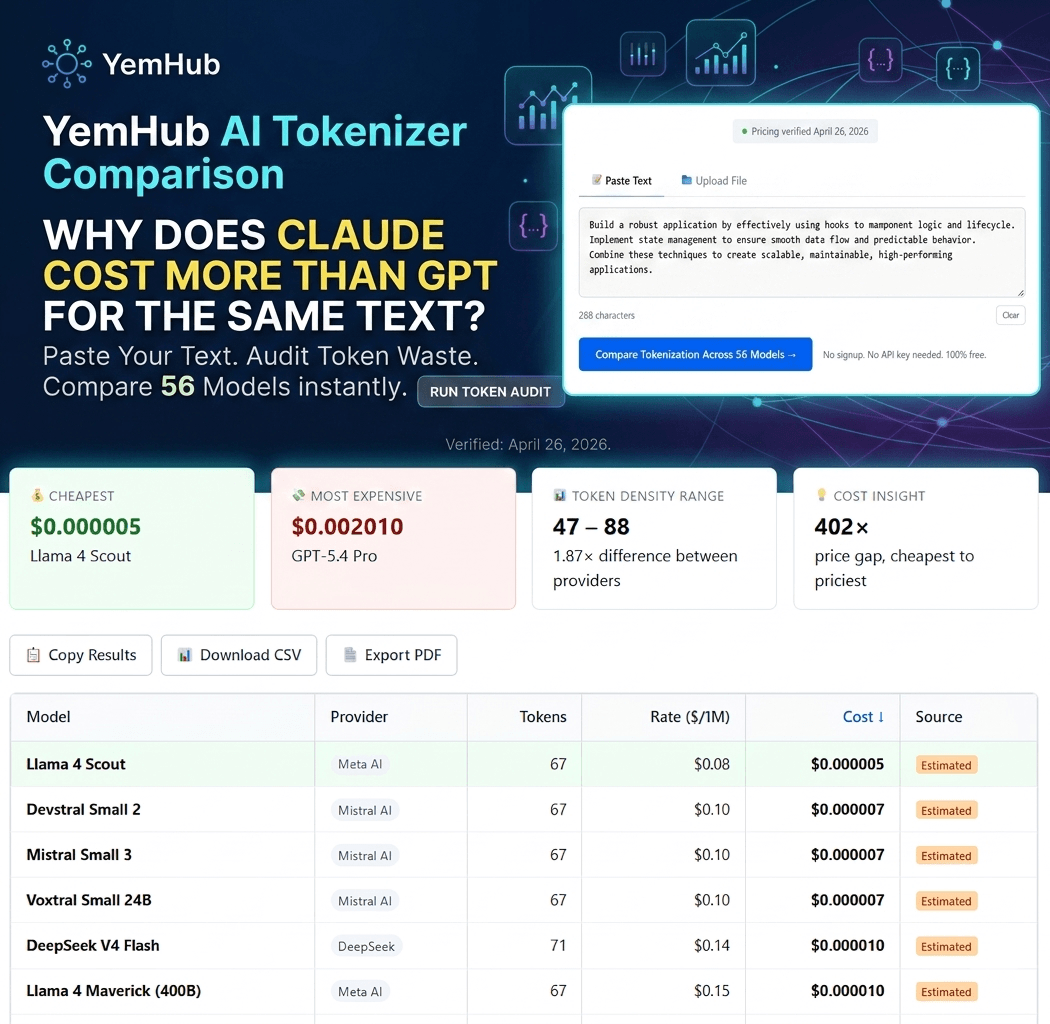
See how the same text tokenizes — and costs — across 56 AI models. The number of tokens for identical input varies by up to 40% between providers.
Computing token counts across all providers...
| Model | Provider | Tokens | Rate ($/1M) | Cost | Source |
|---|
Want to calculate the full cost including outputs?
This page shows input cost only. Get the full breakdown — input + output + caching + batch — in our main calculator.
Open Full Calculator →Why do tokenizers differ?
Every AI model breaks text into "tokens" — small chunks the model processes one at a time. Different providers use different tokenization algorithms. OpenAI uses BPE variants (cl100k_base, o200k_base). Google uses SentencePiece. Anthropic uses a custom v3 tokenizer (introduced with Claude Opus 4.7). For the same English sentence, these can produce token counts that differ by 30–40%, which directly affects what you pay.
Practical impact: If you're sending the same prompt to GPT-5.5 and Claude Opus 4.7, you're not paying the same price even when the per-million-token rate looks identical — because Claude consumes more tokens for the same text.